Streamlined Framework for Large Language Model Training
The NVIDIA NeMo Framework provides a comprehensive solution for training and deploying large language models (LLMs) at scale. It offers end-to-end pipelines, advanced parallelism techniques, and memory optimization strategies to make generative AI model development more efficient and cost-effective.
Key Features and Benefits:
- End-to-end pipelines for data preparation, training, and deployment
- Multiple parallelism techniques like data, tensor, and pipeline parallelism
- Memory-saving methods including selective activation recompute and CPU offloading
- Distributed checkpointing and optimized data loaders
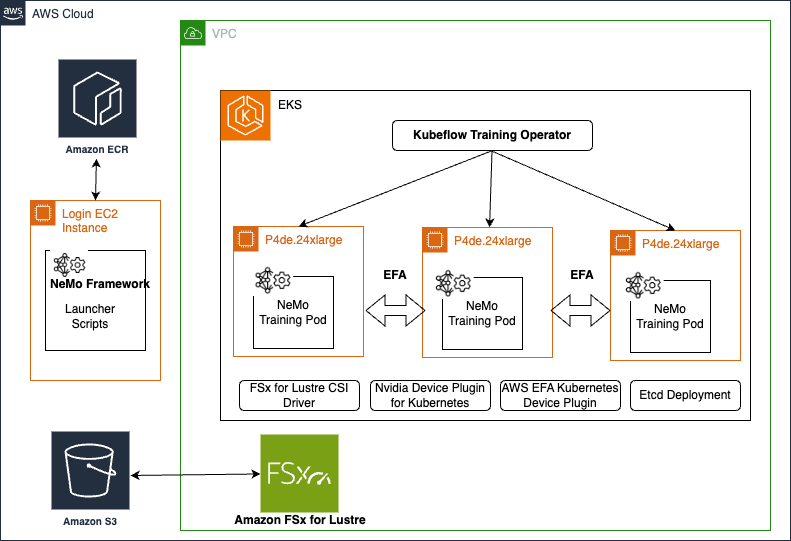
Deploying on Amazon EKS
This guide demonstrates how to run distributed NeMo training workloads on Amazon EKS:
- Set up an EFA-enabled cluster with p4de.24xlarge instances
- Configure an FSx for Lustre file system for shared data storage
- Install required components like the EFA plugin and Kubeflow operators
- Modify NeMo configs and launch data preparation and training jobs
Why It Matters
This solution enables organizations to leverage the power of NeMo and Amazon EKS to efficiently train large AI models. The combination of NeMo’s optimizations and EKS’s managed Kubernetes environment provides a scalable, high-performance platform for advancing generative AI capabilities.









