Understanding Text2Data
Text2Data is a groundbreaking framework designed to improve generative AI’s controllability, particularly in low-resource environments. The framework addresses the challenges of generating data from text when sufficient labeled data is unavailable. It employs a two-stage approach: first mastering data distribution using unlabeled data and then fine-tuning with labeled data while preventing model degradation. This innovative method enhances the ability of generative models to produce high-quality outputs across various domains such as molecular generation, motion capture, and time series analysis.
Key Features of Text2Data
- Utilizes an unsupervised diffusion model to learn from unlabeled data, avoiding semantic ambiguity.
- Implements controllable fine-tuning on labeled data without expanding the dataset, using constraint optimization to prevent catastrophic forgetting.
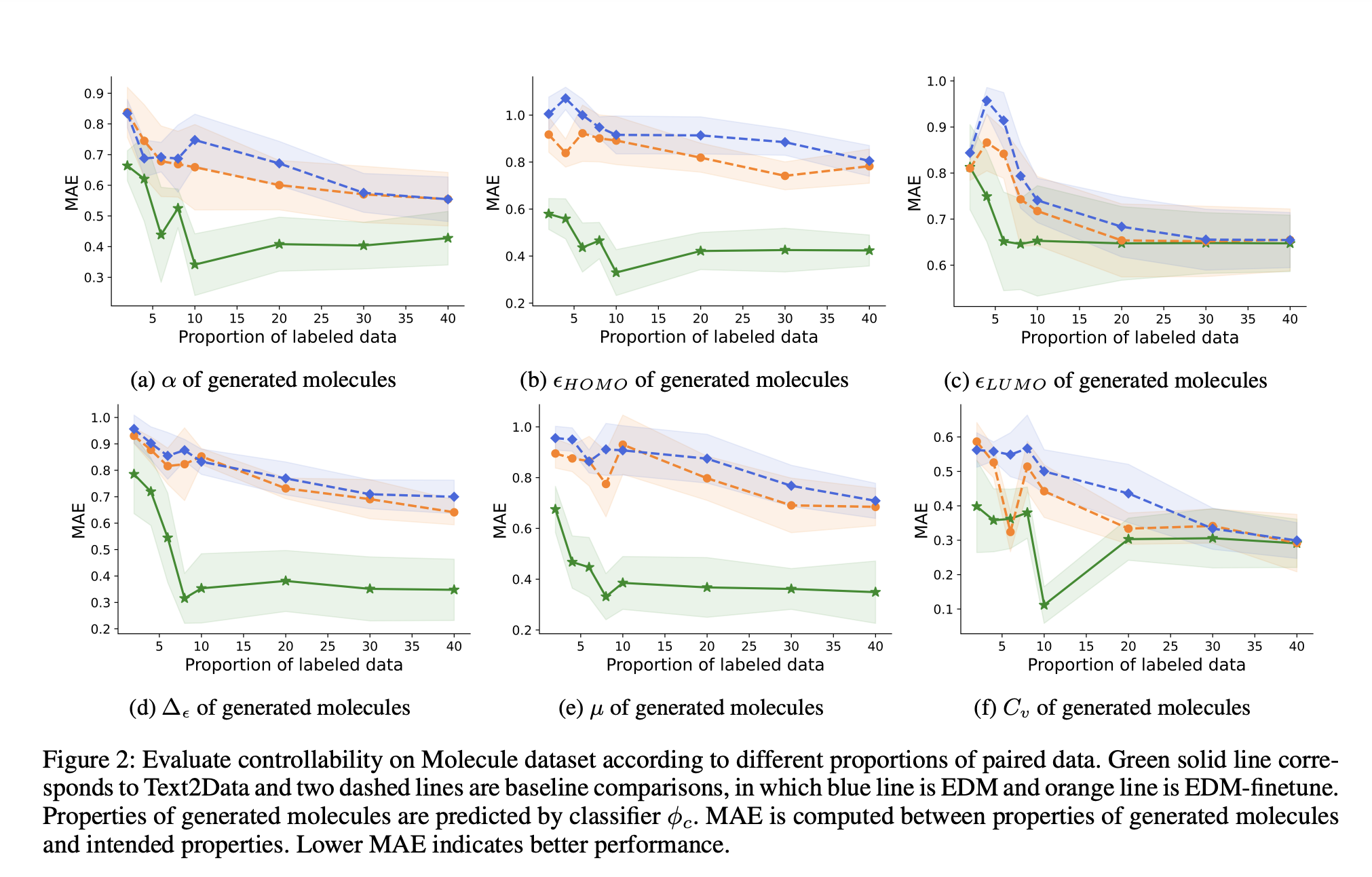
- Achieves superior generation quality and controllability compared to existing methods across multiple domains.
- Provides theoretical validation through rigorous confidence bounds, ensuring the model’s reliability and effectiveness.
Significance of the Framework
Text2Data is crucial for advancing generative AI, especially in fields where data is scarce. By effectively balancing data distribution understanding with controllability, it opens new avenues for applying AI in complex domains. The ability to generate high-quality data with limited resources can lead to significant advancements in research and industry applications, making it a vital tool for future developments in machine learning.









