Large Language Models (LLMs) have shown impressive capabilities in handling various reasoning tasks expressed in natural language, such as math word problems and code generation. However, as the complexity of these tasks increases, LLMs often struggle with errors, hallucinations, and inconsistencies due to their auto-regressive nature. These challenges are particularly pronounced in multi-step reasoning tasks, where the need for more logical, deliberative “System 2” thinking becomes crucial. Traditional methods like Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) have aimed to align LLM outputs with human expectations, but they often require extensive expertise and computational resources.
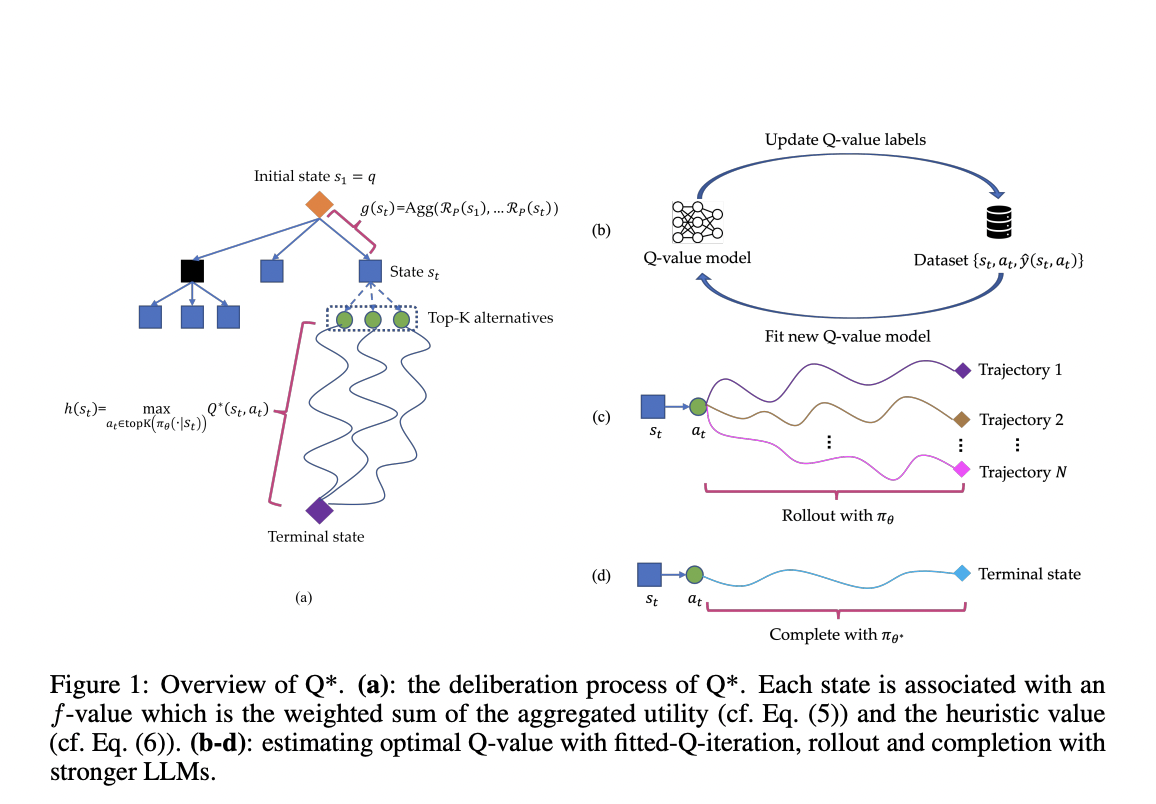
Researchers from Skywork AI and Nanyang Technological University have introduced Q*, a framework designed to enhance the multi-step reasoning capabilities of LLMs through deliberative planning. Q* formalizes LLM reasoning as a Markov Decision Process (MDP) and employs heuristic search methods, like A* search, to guide LLMs in selecting the most promising next steps efficiently. The framework uses a sophisticated architecture that includes offline reinforcement learning, best sequence selection from rollouts, and completion using stronger LLMs for estimating optimal Q-values. These methods allow Q* to learn from training data without task-specific modifications, making it adaptable to various reasoning tasks.
Q* has demonstrated significant performance improvements across multiple reasoning tasks. For instance, it increased the accuracy of Llama-2-7b to 80.8% on the GSM8K dataset and improved Llama-2-7b and DeepSeekMath-7b to 55.4% accuracy on the MATH dataset. In code generation, Q* enhanced CodeQwen1.5-7b-Chat to 77.0% accuracy on the MBPP dataset. These results highlight the framework’s effectiveness in enhancing LLM performance, outperforming traditional methods and some closed-source models. By offering a robust deliberation framework, Q* significantly improves LLMs’ ability to tackle complex multi-step reasoning tasks.









