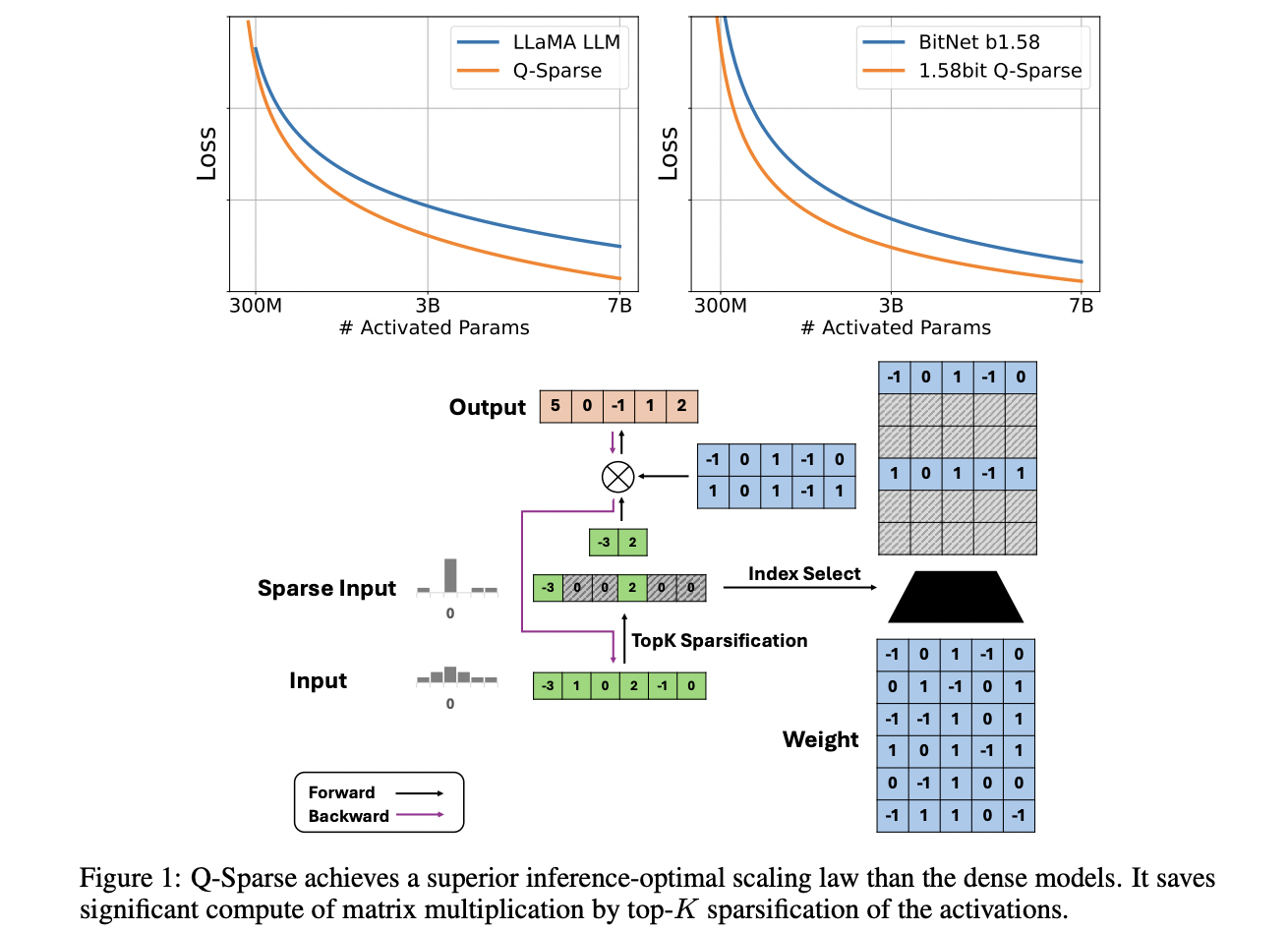
Revolutionizing Language Model Efficiency
Q-Sparse, developed by researchers from Microsoft and the University of Chinese Academy of Sciences, is a groundbreaking approach to training sparsely-activated Large Language Models (LLMs). This innovative method addresses the computational and memory challenges associated with LLM deployment, offering a path to more efficient, cost-effective, and energy-saving language models.
Key Innovations and Findings
- Full activation sparsity achieved through top-K sparsification and straight-through estimator
- Comparable performance to dense baselines with lower inference costs
- Established optimal scaling law for sparsely-activated LLMs
- Effectiveness demonstrated across various training settings
- Compatibility with full-precision and 1-bit models, including BitNet b1.58
Implications for AI Development
Q-Sparse represents a significant leap forward in LLM efficiency, potentially transforming the landscape of natural language processing. By enabling the creation of more resource-efficient models, Q-Sparse paves the way for wider adoption of LLMs in various applications, from mobile devices to large-scale cloud services. This advancement not only promises to reduce the environmental impact of AI but also to democratize access to powerful language models, fostering innovation across industries and research domains.









