The Synthetic Data Challenge
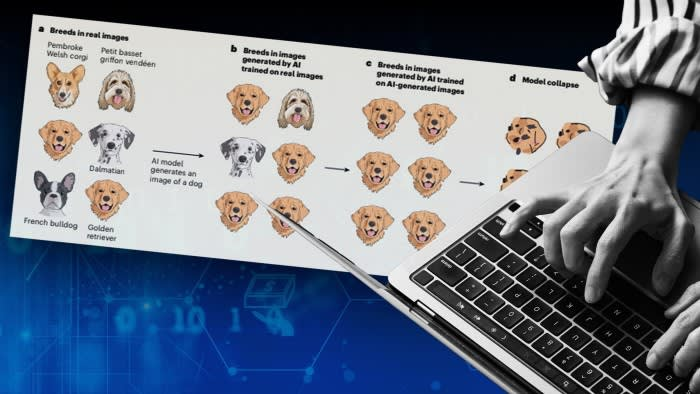
The use of computer-generated data to train AI models is facing scrutiny due to potential risks of producing nonsensical results. Research published in Nature highlights the challenges of using synthetic data for training large language models (LLMs) as companies reach the limits of available human-made material.
Key Findings and Concerns
- Synthetic data usage could lead to rapid degradation of AI models
- One trial using synthetic input text resulted in irrelevant output after fewer than 10 generations
- AI models tend to collapse over time due to accumulation and amplification of mistakes
- Early stages of collapse involve “loss of variance,” favoring majority subpopulations
- Late-stage collapse may result in all parts of the data descending into gibberish
Implications for AI Development
This research underscores the importance of high-quality, human-generated data for AI training. It raises questions about the future of AI development once finite sources of human-made data are exhausted. The findings suggest a potential first-mover advantage for companies that have sourced training data from the pre-AI internet, as their models may better represent the real world. Mitigating these issues remains challenging, with watermarking AI-generated content being one potential solution, though it requires coordination between tech companies.









