Understanding the Research Focus
This research aims to improve the detection of AI-generated texts by using advanced machine learning techniques and generative AI. It emphasizes the importance of a comprehensive dataset that includes various topics and types of content. The dataset consists of over 1.7 million messages, with a balanced mix of human and AI-generated texts. The proposed method combines generative AI capabilities with ensemble learning to enhance feature extraction and text classification.
Key Details of the Methodology
- The dataset includes 837,000 human-generated texts and 900,000 AI-generated texts across diverse topics like politics, health, and technology.
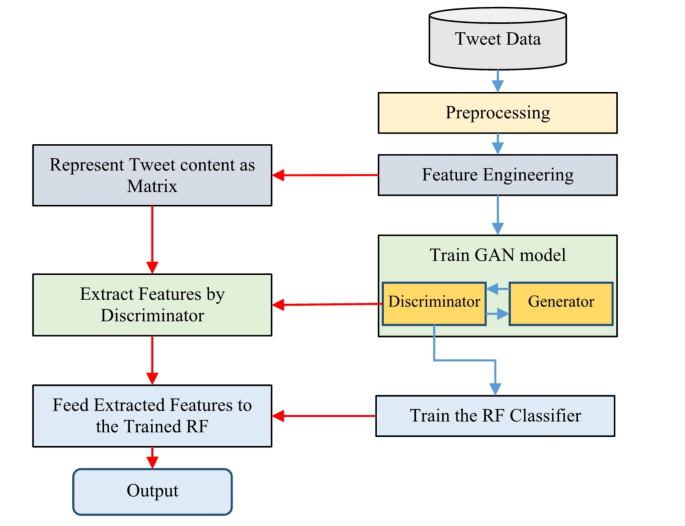
- The preprocessing phase cleans and normalizes the data, removing noise and irrelevant elements to prepare it for analysis.
- A co-occurrence matrix is created to represent word relationships, capturing correlations and significance using TF-IDF measures.
- A GAN model is utilized for feature extraction, focusing on the discriminator to derive informative features for classification.
- Finally, a Random Forest model, enhanced with weighted decision trees, is used for accurate identification of text authorship.
Why This Research Matters
The findings of this study have significant implications for various fields, including cybersecurity, content verification, and information integrity. As AI-generated content becomes more prevalent, the ability to accurately identify its origin is crucial. This research not only provides a robust framework for detecting AI-generated texts but also demonstrates the potential of generative AI in enhancing machine learning applications. By improving detection methods, users can better navigate the complexities of digital content, ensuring the authenticity and reliability of information.